CosmosDB offers MongoDB API access to data. This means that you should be able to take any application you wrote using the Mongo 3.4 wire protocol and point it to CosmosDB rather than a MongoDB instance. Well, kind of.. There are some caveats: Not all operators are supported, the consistency models differ, and the indexing strategy is completely different (exact details here. But other than that - Yay!
So I set out to kick the tires on the MongoDB API, against a cheap, fixed size CosmosDB instance, with the minimum - (400 RU) - allowed throughput.
Good news everyone!
It Just Works ™!
The decision to use CosmosDB as a managed data back end vs. MongoDB is not one you should take lightly. They offerings are not the same at all, even if the MongoDB API provides sufficient parity. One concern that always seems to come up is cost. Rightfully so: the CosmosDB pricing model is based on internal metering of Reserve Units/Second. And while the explanation of what RUs are can be clearly understood, mapping such a low level measurement to your actual workload is not as straightforward.
So how can you calculate your workload’s cost? For write operations, the cost can be easier to estimate. After all, when you insert a document, you can figure out the byte size of the document you are inserting on average, then multiply out by the rate of writing you anticipate.
For queries though, things are a bit more challenging. For one, the number of reads that CosmosDB will perform in order to satisfy your query is not necessarily known ahead of time. Even non-ad-hoc queries can net a highly variable number of documents. It depends on the indexing and the data variety your collection contains. Futher, CosmosDB may internally optimize data access such that some queries seem to have a 1-to-1 cost relation to the number of documents addressed, whereas other queries show lower cost. (I am guessing this is because internal block reads may cover multiple documents when documents are small and adjacent whereas larger ones cull form different or partial other I/O blocks. Just guessing.)
My applications typically produce queries using the MongoDB Aggregation syntax. Some drivers also produce Aggregation expressions, such as C# Linq etc. So I figured the best way to estimate the cost of such queries would be to run them and inquire as to their cost.
To get the cost of an operation, you can chase the operation with a Mongo command, like so:
db.db.adminCommand({ getLastRequestStatistics: 1 }) |
The admin command getLastRequestStatistics returns an object response that looks something like:
{ |
The field - and focus of this post - of interest is RequestCharge. Most importantly: your CosmosDB limits your throughput to whatever RU/s you provisioned for that collection. Therefore, summing up all operation costs in a time window gives you a decent estimate of your overall limits. Conversely, if you know your individual operation costs, you can provision appropriate throughput to match your live workload.
Great! I can issue an aggregation query to MongoDB from my Mongo shell, and then chase it with a “tell me how much was that” inquiry. But that gets tedious quickly… So I wrote this little node app. It’s a single page app that lets you type in various aggregation expressions, run them, and estimate the cost with the click of one button.
The UI lets you put in an aggregation expression (shown) or a “plain” find() query.
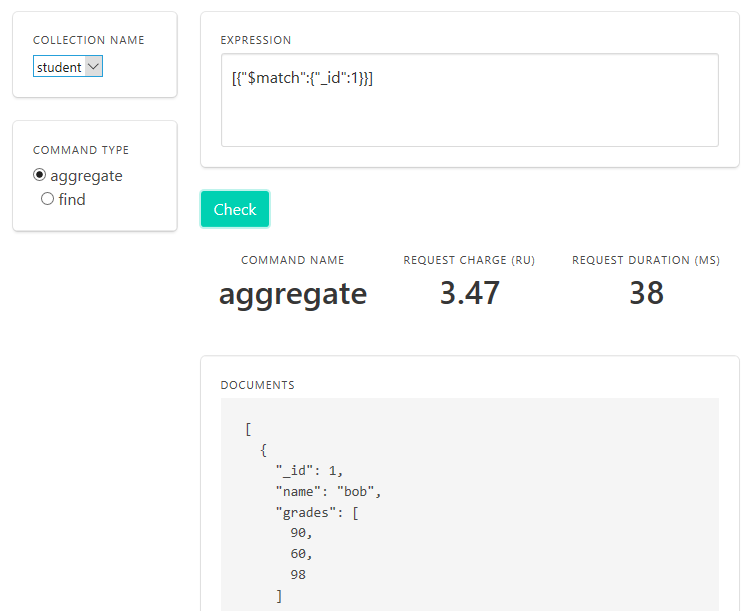
Then hit check to get the cost in terms of RU/s, plus a display of the result of the query. Something like this:
To run the app, you can just clone the source, then run:
node index.js "cosmos-connection-string" |
You will want to do 2 things to the URL you get from the Azure portal as “MongoDB connection string”:
The Azure provided connection string has “==” as part of the password in the URL. Replace these with “%3D%3D” - which is the proper URL encoding for the host portion of the URL.
The Azure provided connection string doesn’t contain the destination database name. You should add the database name into the URL just before the query string, between the “/“ and the “?” characters. For example
...documents.azure.com:10255/mydbname?ssl=true&replicaSet=globaldbspecifies using the database name “mydbname”.
More can be found here on how to get the connection string from the Azure portal.
Another thing to keep in mind is that this is only an estimate. It will vary from your actual runtime load (in either direction!) for various reasons, some of which are:
- The number of documents in your collection changes over time.
- The indexing state and type may differ.
- The partitioning provided by CosmosDB spreads documents over actual storage, and that too can change over time.
- Your queries - especially ad hoc ones composed on arbitrary fields with arbitrary values - can create vastly different queries than the ones you tested or estimated.
As always, reality checks using the actual metrics will beat any estimates produced in the comfort of your own lab. But since this little tool works using a connection string that a developer can get, it can be used even when Azure portal access is not directly available to a developer.