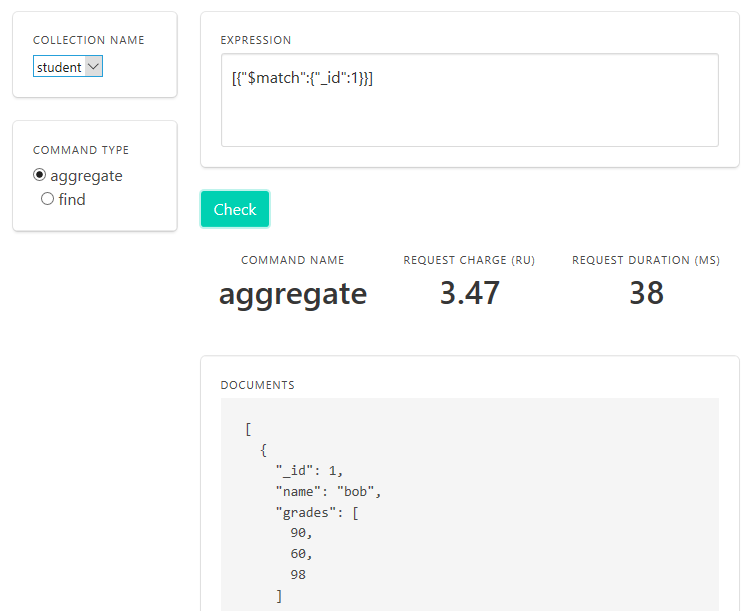
When your document contains an array, $unwind is the aggregation pipeline stage that you most likely need. $unwind lets you un-pivot array elements, so that you can perform specific operations on each (or some) array elements independently.
Why Unwind?
In relational databases, we used to need to pivot rows into columns. Say we had and IoT readings table like this one:
| Device | Measure | Reading | |— |— |— |— | | 1 | ‘Temp’ | 42 | 1:00 | | 1 | ‘Speed | 91 | 1:00 | | 2 | ‘Speed’ | 94 | 1:00 | 2 | ‘Temp’ | 33 | 1:00 | | 2 | ‘Temp’ | 37 | 2:00 |
And we want a query to return results such as:
| Device | Speed | Temp | Time |
|---|---|---|---|
| 1 | 91 | 42 | 1:00 |
| 2 | 94 | 33 | 1:00 |
| 2 | 37 | 2:00 |
We can achieve that with a SQL pivoting function. The need to pivot stems from the model in which each “soft property” in the data table. We didn’t want to create a column for each measure, and we didn’t want to add a column to the table each time a new measure is needed.
In MongoDB (and any other document oriented database), the model for a single reading document might look more like the one below. Each document is a point in time that contains a bunch of measures. If ever a new measure was added - no problem! An extra element can be added to the array with no schema change. If ever a reading had more or fewer readings at a point in time - no problem either. The array contains a set of readings which can grow or shrink.
{ |
With this document model, we would not need to do anything special for the report of readings by hour. The document already contains relevant measurements for each time period.
But if we wanted to calculate the average temperature across the devices, we’d need to do some digging. We don’t want to average every readings.value field - only the ones labeled 'temp'.
Using the aggregation framework and $unwind we can do this in 3 steps:
- Unwind the
readingsarray. - Filter out anything except
'temp'. - Perform
$avgon the values.
How to Unwind?
Let’s do this step by step. First, just unwind the array
db.readings.aggregate([ |
The result of $unwind is that for each original document’s readings array element, a new document will be produces that contains all the fields from the original document, but only one element assigned to the value of readings. As you can see above, the data type of the field readings after $unwind became a single-valued field rather than the original array. Device 1 had 2 elements in the original document, so in the $unwind output we have 2 documents, each attached to one element from the original array. One document contains a single reading for the measurement named speed, another document contains a reading for temperature measurement named temp.
Next step - we want only the temperature readings, getting rid of any speed or other measurements that may exist. We can do this with the $match pipeline stage. $match filters documents and only emits ones that match the criteria supplied - just like find() does.
db.readings.aggregate([ |
This got rid of any measurements that were not labeled temp. With temperature only values in hand, we can now calculate average temperature.
The $group pipeline operator will let us calculate an average for each device:
db.readings.aggregate([ |
The behavior of $unwind evolved over time, matching common usage patterns and expectation the community found useful. Several scenarios and special cases arise when unwinding arrays:
- What if the document contains a field with a single value - not an array?
- What if the array has no elements?
- What if the document contains no such field at all?
All these need to be handled in some way, and understanding the behavior would help you avoid fluky results.
Since MongoDB version 3.2, $unwind treats a target field containing a scalar or non-array value as if it were a single element array containing that one non-array value. These two documents are treated the same way by $unwind:
{ |
Device 3 above has a single reading in the readings field - not an array. Device 4 has a single-element array for readings. Since $unwind treats them the same, we don’t neat fancy $project and $cond checks to normalize input documents (Squee!). If we added these documents to the readings collection, and ran the same 3 stage pipeline as before, we’d get the results we expect. Prior to mongo 3.2, a non-array field handed to $unwind would have produced an error.
db.readings.aggregate([ |
The Nitty Gritty
Now what about a missing field, an empty array, or a field containing null? Here are examples of these documents:
{ device: 10, time: ISODate('2019-01-31T06:00:00Z') } |
If we ran $unwind on those documents, none of them would be emitted past $unwind. The example below passes documents with device == 10 to $unwind, but since none of them had a “useful” readings value to attach to an output document - none of them got emitted:
db.readings.aggregate([ |
This is just a behavior though. the word “useful” in our case where we won’t want an empty or missing reading to pollute our averaging math is our choice. Other use cases may exist where you actually want every document entering $unwind to be emitted forward even if it doesn’t have an array element to contribute. If you want that behavior, you can use the option preserveNullAndEmptyArrays set to true. To supply this option though, you would need to use a slightly different argument to $unwind. Until now, we gave $unwind a bare value-of-field argument $<field name>. The more elaborate syntax is {$unwind: { path: '$<field name>'}}. The following two forms are identical in meaning:
{ $unwind: '$readings' } |
The latter expression is where we can add our preserveNullAndEmptyArrays option. Putting it all together looks like this:
db.readings.aggregate([ |
This time, a single document was emitted corresponding to each of the incoming device 10 documents. For each of those 3 documents, MongoDB considered that the incoming document has to be emitted out at least once. But what value should the output document have? In the case of the document containing readings: null, mongo emitted a null in the readings field. For the ones with missing field and with the array containing no value, $unwind emitted a document with no readings field at all. The notion is that a missing field should be preserved - no invention of a non-existing field. As far as an existing but empty array - think of it as “a document with no value there”. Emitting a field would have required a value to be assigned to the field. The value null is still a value and is not the same as not having any value. If mongo would have emitted a {readings: null} field in response to an empty array that’s like saying that the original document had an array element null - which is not the case. Bottom line: the behavior is defined in a certain way. We can leverage it when we need to, and we can also manipulate the fields further using other pipeline operators.
Unwind Without $unwind?
The three-step pipeline to calculate average is not very difficult to read, understand, or produce. But the real need is expressed in the $group stage. The stages for filtering and unwinding were cruft that adds verbiage - but not for nothing.
Tempted to shorten the syntax, one might think to use some of the projection operators, such as $filter or $arrayToObject. The $filter example would go something along the lines of:
db.readings.aggregate([ |
Where we can pluck only the 'temp' elements out of the readings array. This works, but must be preceded by something to ensure that readings is actually an array. Unlike the more forgiving $unwind, $filter insists that the input field is an array or it produces an error. That’s why I included a $match that only passes along documents where that condition holds true (See BSON spec for type information. 0x04 is Array). This seems almost palatable, but would still require more syntax to transform the one-element array to something we can use directly for the math. So since the amount of text required to achieve the goal is not reduced, and the overall pipeline does not become more readable, I see little reason to go to those lengths.
Conclusion
$unwind is an important pipeline stage in the document-oriented world. Dealing with arrays and aggregation will undoubtedly get you using $unwind sooner or later. In a previous post we focused on data scenarios where this all made sense. In this post, we focused more on the balance between syntax and the meaning of the stage and related operators. Either way, it’s well worth learning the nuanced behavior of this key pipeline stage.




 Expanding that side bar gives you a tree view for the databases (yes, plural: you can have several connected at once).
Expanding that side bar gives you a tree view for the databases (yes, plural: you can have several connected at once).